

Руководство администратора
В данном руководстве рассматривается развертывание и управление Tarantool-кластером с помощью Tarantool Cartridge.
Примечание
Подробнее про управление экземплярами Tarantool см. в руководстве по Tarantool, в разделе Администрирование сервера.
Перед тем, как развертывать кластер, ознакомьтесь с понятием кластерных ролей и разверните экземпляры Tarantool в соответствии с предполагаемой топологией кластера.
Cartridge is compatible with Tarantool 1.10 and Tarantool 2.x. Cartridge doesn’t support Tarantool 3.0 and higher.
| Tarantool 1.10 | Tarantool 2.8 | Tarantool 2.10 | Tarantool 2.11 | Additional notes | |
|---|---|---|---|---|---|
| Cartridge 2.10.0 | + | + | + | + | |
| Cartridge 2.9.0 | + | + | + | + | Can’t be downgraded to Cartridge 2.7.9 and lower |
| Cartridge 2.8.6 | + | + | + | + | |
| Cartridge 2.8.5 | + | + | + | + | |
| Cartridge 2.8.4 | + | + | + | + | |
| Cartridge 2.8.3 | + | + | + | + | |
| Cartridge 2.8.2 | + | + | + | + | |
| Cartridge 2.8.1 | + | + | + | + | |
| Cartridge 2.8.0 | + | + | + | + | |
| Cartridge 2.7.9 | + | + | + | + | |
| Cartridge 2.7.8 | + | + | + | - | Update to this release is broken |
| Cartridge 2.7.7 | + | + | + | - | Update to this release is broken |
| Cartridge 2.7.6 | + | + | + | - | Update to this release is broken |
| Cartridge 2.7.5 | + | + | + | - | |
| Cartridge 2.7.4 | + | + | + | - | |
| Cartridge 2.7.3 | + | + | - | - | |
| Cartridge 2.7.2 | + | + | - | - | |
| Cartridge 2.7.1 | + | + | - | - | |
| Cartridge 2.7.0 | + | + | - | - | Can’t be downgraded to Cartridge 2.6.0 and lower |
Чтобы развернуть кластер, сначала настройте все экземпляры Tarantool в соответствии с предполагаемой топологией кластера, например:
my_app.router: {"advertise_uri": "localhost:3301", "http_port": 8080, "workdir": "./tmp/router"}
my_app.storage_A_master: {"advertise_uri": "localhost:3302", "http_enabled": False, "workdir": "./tmp/storage-a-master"}
my_app.storage_A_replica: {"advertise_uri": "localhost:3303", "http_enabled": False, "workdir": "./tmp/storage-a-replica"}
my_app.storage_B_master: {"advertise_uri": "localhost:3304", "http_enabled": False, "workdir": "./tmp/storage-b-master"}
my_app.storage_B_replica: {"advertise_uri": "localhost:3305", "http_enabled": False, "workdir": "./tmp/storage-b-replica"}
Затем, запустите экземпляры, например, используя CLI в cartridge:
$ cartridge start my_app --cfg demo.yml --run-dir ./tmp/run
cartridge-cliis deprecated in favor of the tt CLI utility.- This guide uses
cartridge-clias a native tool for Cartridge applications development. However, we encourage you to switch tottin order to simplify the migration to Tarantool 3.0 and newer versions.
И задайте предварительные настройки для кластера, что можно сделать через веб-интерфейс по адресу http://<instance_hostname>:<instance_http_port> (в этом примере http://localhost:8080).
You can bootstrap a cluster from an existing cluster (original cluster in the example
below) via the argparse option TARANTOOL_BOOTSTRAP_FROM or --bootstrap_from
in the following form:
TARANTOOL_BOOTSTRAP_FROM=admin:SECRET-ORIGINAL-CLUSTER-COOKIE@HOST:MASTER_PORT,....
That option should be present on each instance in replicasets of the target cluster.
Make sure that you’ve prepared a valid configuration for the target cluster.
A valid topology should contain the same replicaset uuids for each replicaset
and instance uuids that differ from original cluster. You can list several instances in this option.
This is required for the latests Tarantool bootstrap policy.
Several notes:
- You can bootstrap specific replicasets from a cluster (for example, data nodes only) instead of the whole cluster.
- Don’t load data in the target cluster while bootstrapping. If you need to hot switch between original and target cluster, stop data loading in original cluster until bootstrapping is completed.
- Check logs and
box.info.replicationon target cluster after bootstrapping. If something went wrong, try again.
Example of valid data in edit_topology request:
Original cluster topology:
{
"replicasets": [
{
"alias": "router-original",
"uuid": "aaaaaaaa-aaaa-0000-0000-000000000000",
"join_servers": [
{
"uri": "localhost:3301",
"uuid": "aaaaaaaa-aaaa-0000-0000-000000000001"
}
],
"roles": ["vshard-router", "failover-coordinator"]
},
{
"alias": "storage-original",
"uuid": "bbbbbbbb-0000-0000-0000-000000000000",
"weight": 1,
"join_servers": [
{
"uri": "localhost:3302",
"uuid": "bbbbbbbb-bbbb-0000-0000-000000000001"
}
],
"roles": ["vshard-storage"]
}
]
}
Target cluster topology:
{
"replicasets": [
{
"alias": "router-original",
"uuid": "cccccccc-cccc-0000-0000-000000000000", // <- this is dataless router,
// it's not necessary to bootstrap it from original cluster
"join_servers": [
{
"uri": "localhost:13301", // <- different uri
"uuid": "cccccccc-cccc-0000-0000-000000000001"
}
],
"roles": ["vshard-router", "failover-coordinator"]
},
{
"alias": "storage-original",
"uuid": "bbbbbbbb-0000-0000-0000-000000000000", // replicaset_uuid is the same as in the original cluster
// that allows us bootstrap target cluster from original cluster
"weight": 1,
"join_servers": [
{
"uri": "localhost:13302", // <- different uri
"uuid": "bbbbbbbb-bbbb-0000-0000-000000000002" // <- different instance_uuid
}
],
"roles": ["vshard-storage"]
}
]
}
В веб-интерфейсе выполните следующие действия:
В зависимости от статуса аутентификации:
Если аутентификация включена (в эксплуатационной среде), введите свои учетные данные и нажмите Login (Войти):

Если отключен (для удобства тестирования), просто переходите к настройке кластера.
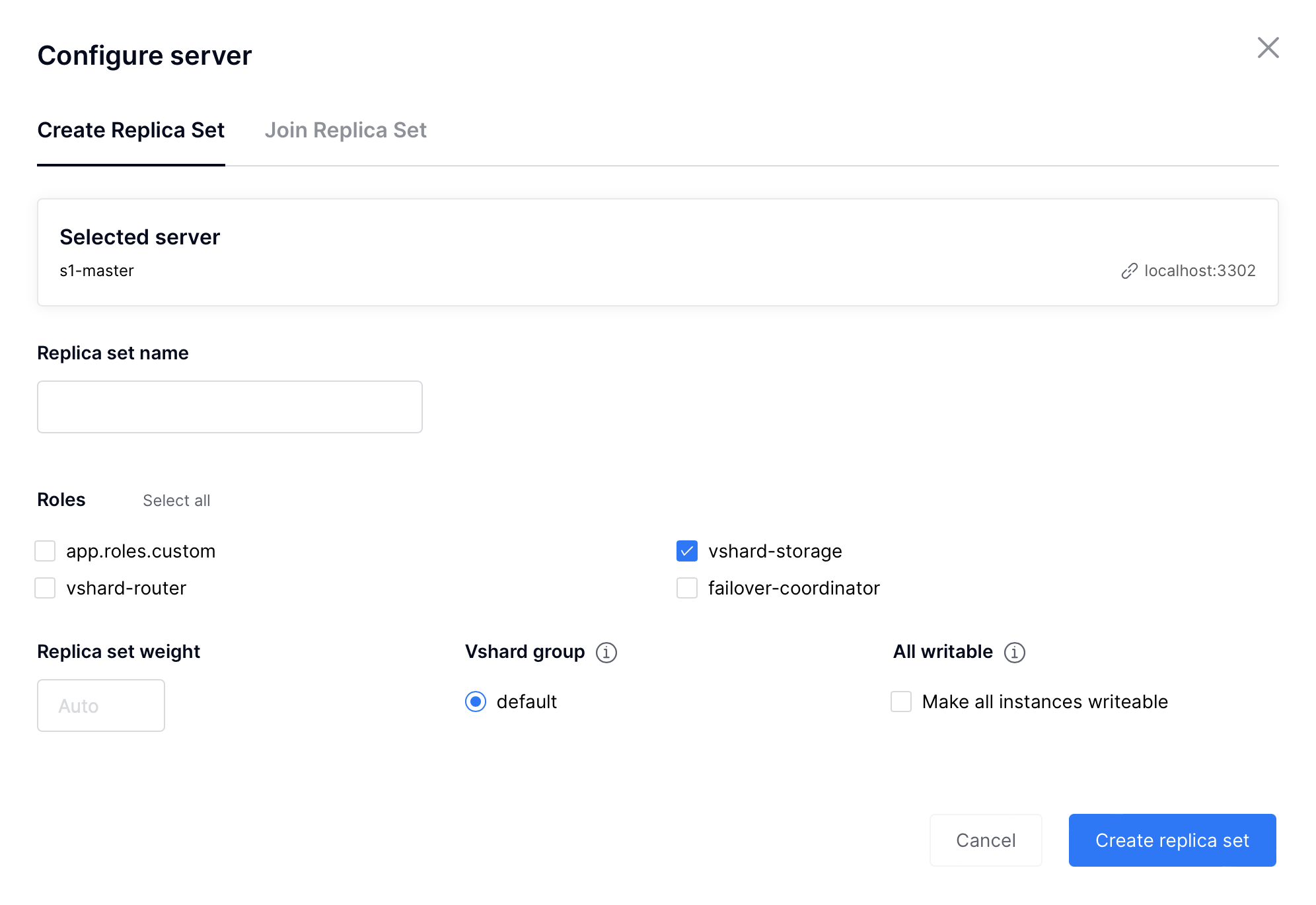
Нажмите Configure (Настроить) рядом с первым ненастроенным сервером, чтобы создать первый набор реплик исключительно для роутера (для обработки ресурсоемких вычислений).

Во всплывающем окне выберите роль
vshard-routerили любую другую пользовательскую роль, для которой рольvshard-routerбудет зависимой (в данном примере это пользовательская роль с именемapp.roles.api).(Необязательно) Укажите отображаемое имя для набора реплик, например
router.
Примечание
Как описано в разделе о встроенных ролях, рекомендуется включать кластерные роли в зависимости от рабочей нагрузки на экземпляры, которые работают на физических серверах с аппаратным обеспечением, предназначенным для рабочей нагрузки определенного типа.
Нажмите Create replica set (Создать набор реплик), и созданный набор реплик отобразится в веб-интерфейсе

Предупреждение
Обратите внимание: после того, как экземпляр подключится к набору реплик, НЕВОЗМОЖНО это отменить или переподключить его к другому набору реплик.
Создайте новый набор реплик для мастер-узла хранения данных (для обработки большого количества транзакций).
Выберите роль
vshard-storageили любую другую пользовательскую роль, для которой рольvshard-storageбудет зависимой (в данном примере это пользовательская роль с именемapp.roles.storage).(Необязательно) Задайте определенную группу, например
hot(горячие). Наборы реплик с ролямиvshard-storageмогут относиться к различным группам. В нашем примере группыhotиcoldпредназначены для независимой обработки горячих и холодных данных соответственно. Эти группы указаны в конфигурационном файле кластера. По умолчанию, кластер не входит ни в одну группу.(Необязательно) Укажите отображаемое имя для набора реплик, например
hot-storage.Нажмите Create replica set (Создать набор реплик).
(Необязательно) Если этого требует топология, добавьте во второй набор реплик дополнительные хранилища:
Нажмите Configure (Настроить) рядом с другим ненастроенным сервером, который выделен для рабочей нагрузки с большим количеством транзакций.
Нажмите на вкладку Join Replica Set (Присоединиться к набору реплик).
Выберите второй набор реплик и нажмите Join replica set (Присоединиться к набору реплик), чтобы добавить к нему сервер.

В зависимости от топологии кластера:
- добавьте дополнительные экземпляры к первому или второму набору реплик, или же
- создайте дополнительные наборы реплик и добавьте в них экземпляры для обработки определенной рабочей нагрузки (вычисления или транзакции).
Например:

(Необязательно) По умолчанию все новые наборы реплик
vshard-storageполучают вес, равный1, до загрузкиvshardв следующем шаге.
Примечание
Если вы добавите новый набор реплик после начальной загрузкиvshard, как описано в разделе об изменении топологии, он по умолчанию получит вес 0.Чтобы разные наборы реплик хранили разное количество сегментов, нажмите Edit (Изменить) рядом с набором реплик, измените значение веса по умолчанию и нажмите Save (Сохранить):

Для получения дополнительной информации о сегментах и весах набора реплик см. документацию по модулю vshard.
Загрузите
vshard, нажав соответствующую кнопку или же выполнив командуcartridge.admin.boostrap_vshard()в административной консоли.Эта команда создает виртуальные сегменты и распределяет их по хранилищам.
С этого момента всю настройку кластера можно выполнять через веб-интерфейс.

Конфигурация кластера задается в конфигурационном файле формата YAML. Этот файл включает в себя топологию кластера и описания ролей.
У всех экземпляров в кластере Tarantool одинаковые настройки. Для этого каждый экземпляр в кластере хранит копию конфигурационного файла, а кластер синхронизирует эти копии: как только вы подтверждаете обновление конфигурации в веб-интерфейсе, кластер валидирует ее (и отклоняет неприемлемые изменения) и передает ее автоматически по всему кластеру.
Чтобы обновить конфигурацию:
Нажмите на вкладку Configuration files (Конфигурационные файлы).
(Необязательно) Нажмите Downloaded (Загруженные), чтобы получить текущую версию конфигурационного файла.
Обновите конфигурационный файл.
Можно добавлять/изменять/удалять любые разделы, кроме системных:
topology,vshardиvshard_groups.Чтобы удалить раздел, просто удалите его из конфигурационного файла.
Click Upload configuration button to upload configuration file.
В нижней части экрана вы увидите сообщение об успешной загрузке конфигурации или ошибку, если новые настройки не были применены.
В данной главе описывается, как:
- изменять топологию кластера,
- включать автоматическое восстановление после отказа,
- вручную менять мастера в наборе реплик,
- отключать наборы реплик,
- исключать экземпляры.
При добавлении нового развернутого экземпляра в новый или уже существующий набор реплик:
Кластер валидирует обновление конфигурации, проверяя доступность нового экземпляра с помощью модуля membership.
Примечание
Модуль
membershipработает по протоколу UDP и может производить операции до вызова функцииbox.cfg.Все узлы в кластере должны быть рабочими, чтобы валидация была пройдена.
Новый экземпляр ожидает, пока другой экземпляр в кластере не получит обновление конфигурации (оповещение реализовано с помощью того же модуля
membership). На этом шаге у нового экземпляра еще нет своего UUID.Как только новый экземпляр понимает, что кластер знает о нем, экземпляр вызывает функцию box.cfg и начинает работу.
Оптимальная стратегия подключения новых узлов к кластеру состоит в том, чтобы развертывать новые экземпляры в наборе реплик с нулевым весом для каждого экземпляра, а затем увеличивать вес. Как только вес обновится и все узлы кластера получат уведомление об изменении конфигурации, сегменты начинают мигрировать на новые узлы.
Чтобы добавить в кластер новые узлы, выполните следующие действия:
Разверните новые экземпляры Tarantool, как описано в разделе по развертыванию.
Если новые узлы не появились в веб-интерфейсе, нажмите Probe server (Найти сервер) и укажите их URI вручную.

Если узел доступен, он появится в списке.
В веб-интерфейсе:
Создайте новый набор реплик с одним из новых экземпляров: нажмите Configure (Настроить) рядом с ненастроенным сервером, отметьте флажками необходимые роли и нажмите Create replica set (Создать набор реплик):
Примечание
Если вы добавляете экземпляр
vshard-storage, следует помнить, что вес всех таких экземпляров по умолчанию становится равным0после начальной загрузкиvshard, которая происходит во время первоначального развертывания кластера.
Или добавьте дополнительные экземпляры к существующему набору реплик: нажмите Configure (Настроить) рядом с ненастроенным сервером, нажмите на вкладку Join replica set (Присоединиться к набору реплик), выберите набор реплик и нажмите Join replica set.
При необходимости повторите действия для других экземпляров, чтобы достичь необходимого уровня резервирования.
При развертывании нового набора реплик
vshard-storageзаполните необходимую информацию: нажмите Edit (Изменить) рядом с необходимым набором реплик, увеличьте его вес и нажмите Save (Сохранить), чтобы начать балансировку данных.
Вместо веб-интерфейса можно использовать GraphQL для просмотра и изменения топологии кластера. Конечная точка кластера для выполнения запросов GraphQL — /admin/api. Можно пользоваться любыми сторонними клиентами, поддерживающими GraphQL, например GraphiQL или Altair.
Примеры:
вывод списка всех серверов в кластере:
query { servers { alias uri uuid } }
вывод списка всех наборов реплик с серверами:
query { replicasets { uuid roles servers { uri uuid } } }
подключение сервера к новому набору реплик с включенной ролью хранилища:
mutation { join_server( uri: "localhost:33003" roles: ["vshard-storage"] ) }
Балансировка (решардинг) запускается через определенные промежутки времени и при добавлении в кластер нового набора реплик с весом, отличным от нуля. Для получения дополнительной информации см. раздел по балансировке в документации по модулю vshard.
Самый удобный способ мониторинга процесса балансировки заключается в том, чтобы отслеживать количество активных сегментов на узлах хранения. Сначала в новом наборе реплик 0 активных сегментов. Через некоторое время фоновый процесс балансировки начинает переносить сегменты из других наборов реплик в новый. Балансировка продолжается до тех пор, пока данные не будут распределены равномерно по всем наборам реплик.
Чтобы отслеживать текущее количество сегментов, подключитесь к любому экземпляру Tarantool через административную консоль и выполните команду:
tarantool> vshard.storage.info().bucket
---
- receiving: 0
active: 1000
total: 1000
garbage: 0
sending: 0
...
Количество сегментов может увеличиваться или уменьшаться в зависимости от того, переносит ли балансировщик сегменты в узел хранения или из него.
Для получения дополнительной информации о параметрах мониторинга см. раздел по мониторингу хранилищ.
Под отключением всего набора реплик (например, для технического обслуживания) подразумевается перемещение всех его сегментов в другие наборы реплик.
Чтобы отключить набор реплик, выполните следующие действия:
Нажмите Edit (Изменить) рядом с необходимым набором реплик.
Укажите
0как значение веса и нажмите Save (Сохранить):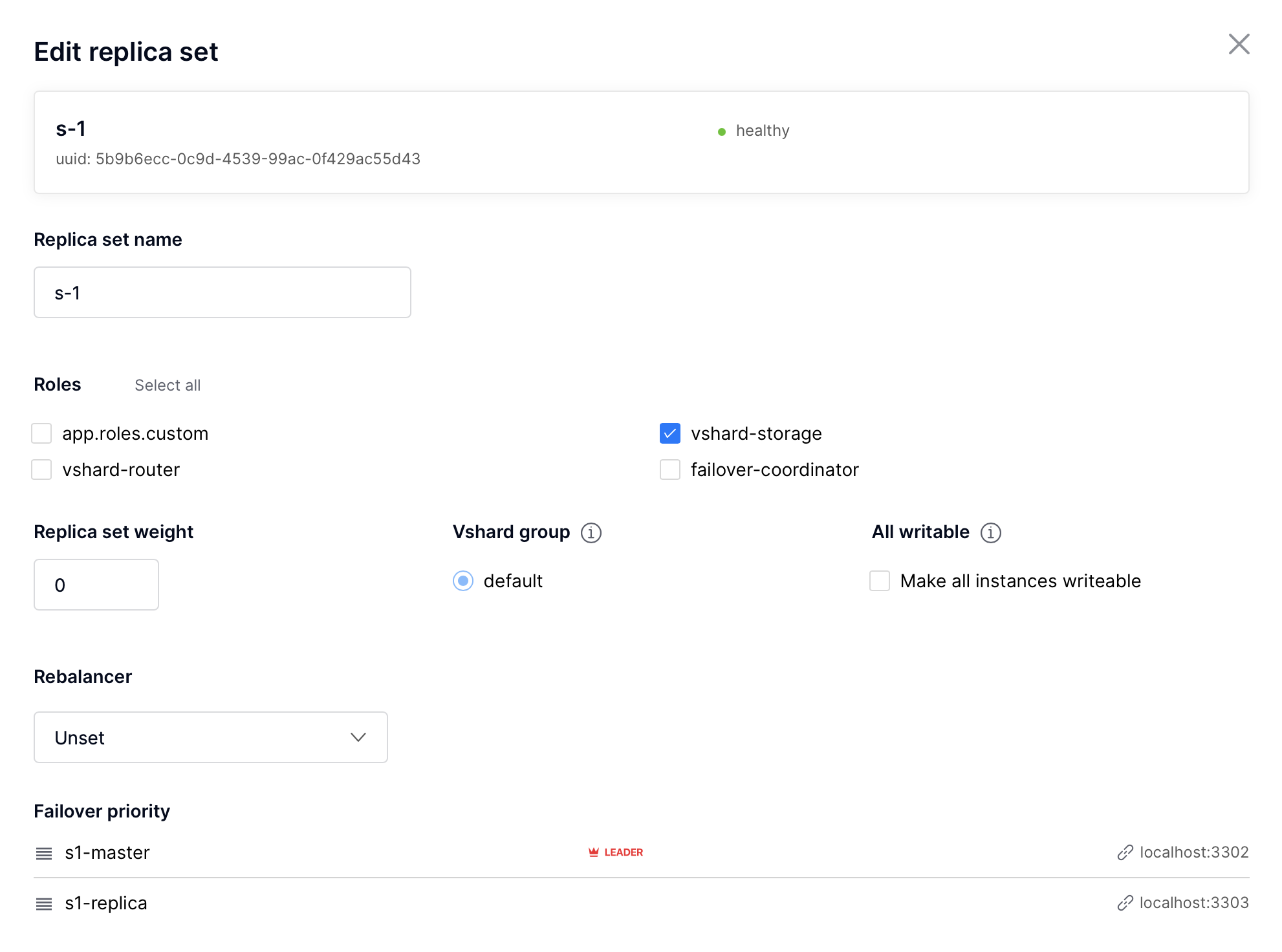
Подождите, пока процесс балансировки не завершит перенос всех сегментов набора. Можно отслеживать текущее количество сегментов, как описано в разделе по балансировке данных.
Sometimes when instances are not healthy, you may want to disable them to perform some operations on cluster (e.g. apply new cluster config).
To disable an instance, click … next to it, then click Disable server:
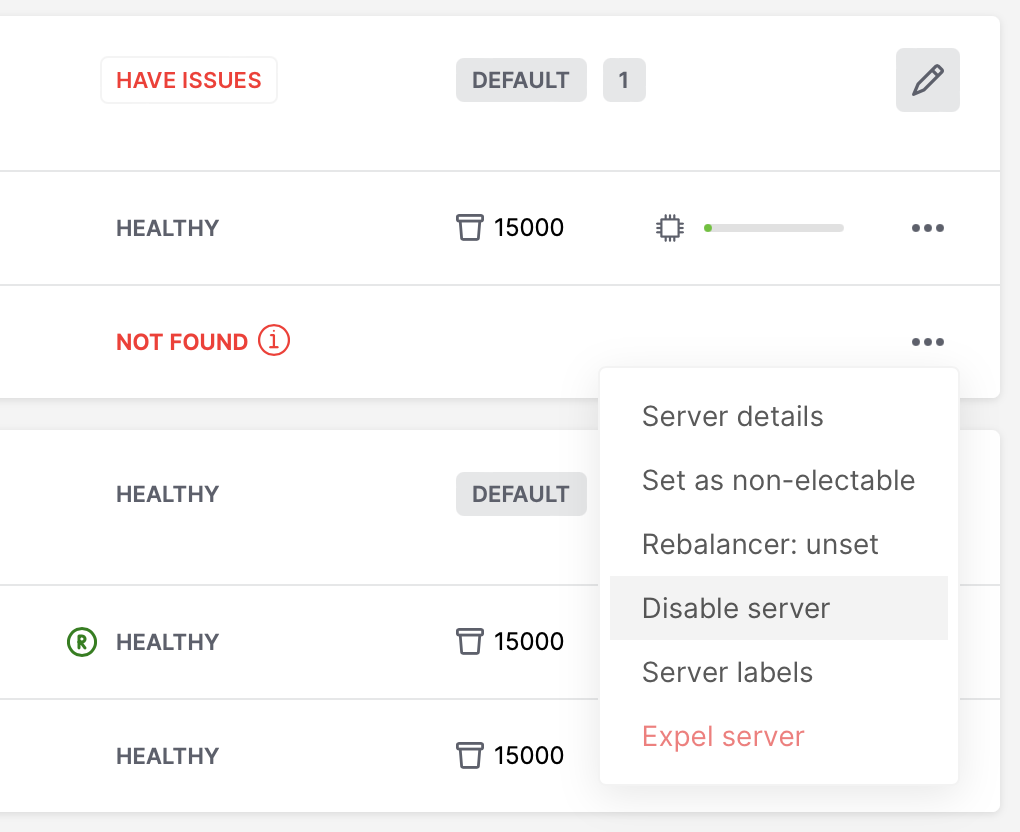
Then instance will be marked as disabled and will not participate in cluster configuration:

You can also disable an active leader, then the leader will be switched to another instance.
Примечание
Don’t forget to enable instance back after you fix them!
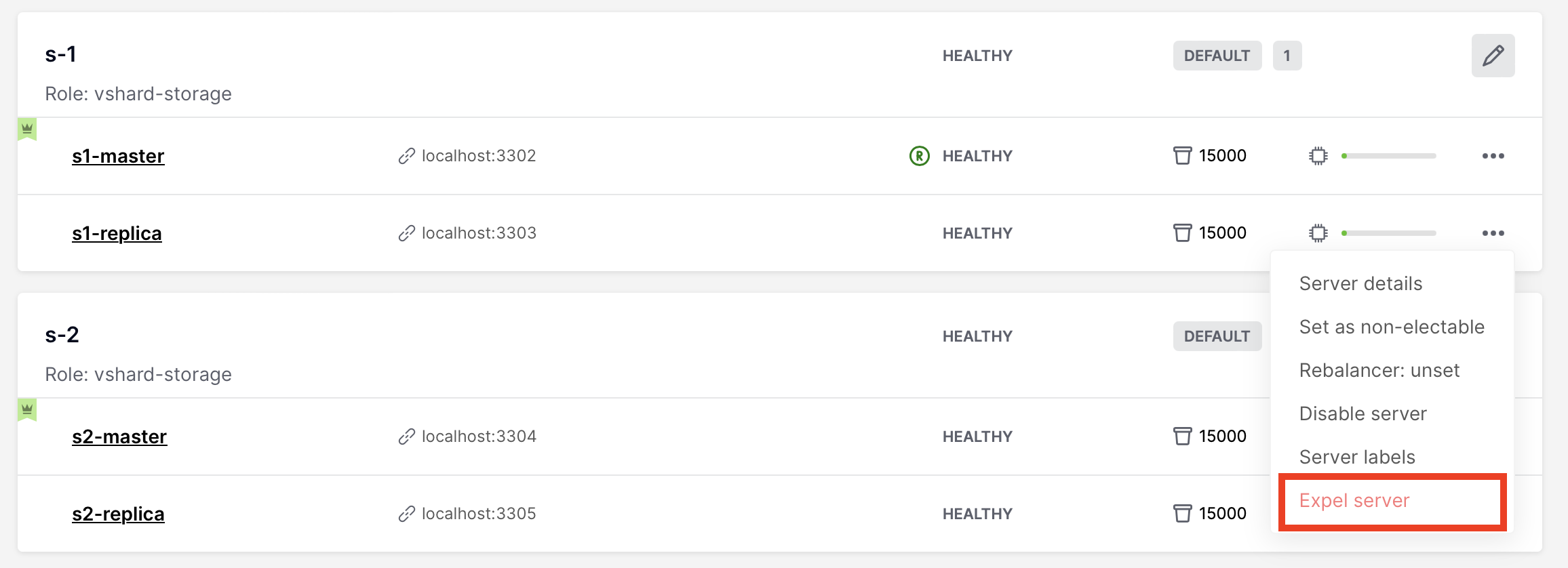
После того, как экземпляр будет исключен из кластера, он никогда не сможет снова участвовать в кластере, поскольку ни один экземпляр не будет принимать его.
To expel an instance, stop it, then click … next to it, then click Expel server and Expel:
Примечание
Есть два ограничения:
- Нельзя исключить лидера, если у него есть реплика. Сначала передайте роль лидера.
- Нельзя исключить vshard-хранилище, если оно хранит сегменты. Установите значение веса на 0 и дождитесь завершения ребалансировки.
Since Cartridge 2.8.0 you will see an issue if you had a replica set with an
expelled instance in box.space._cluster. You can fix it by manually remove expelled
instance from box.space._cluster:
-- call thin on leader:
local confapplier = require('cartridge.confapplier')
local topology = require('cartridge.topology')
local topology_cfg = confapplier.get_readonly('topology')
local fun = require('fun')
for _, uuid, _ in fun.filter(topology.expelled, topology_cfg.servers) do
box.space._cluster.index.uuid:delete(uuid)
end
Примечание
- Do not expel instances until they’re stopped.
- Do not forget to clean expelled instence’s data directory and remove it from your pipelines.
- You can not return expelled instance to the cluster.
In a master-replica cluster configuration with automatic failover enabled, if the user-specified master of any replica set fails, the cluster automatically chooses a replica from the priority list and grants it the active master role (read/write). To learn more about details of failover work, see failover documentation.
The leader is the first instance according to the topology configuration.
No automatic decisions are made. You can manually change the leader in the failover
priority list or call box.cfg{read_only = false} on any instance.
To disable failover:
Нажмите Failover (Восстановление после отказа):

In the Failover control box, select the Disabled mode:

Важно
The eventual failover mode is not recommended for use on large clusters
in production. If you have a high load production cluster, use the stateful
failover with etcd instead.
The leader isn’t elected consistently. Every instance thinks the leader is the first healthy server in the replicaset. The instance health is determined according to the membership status (the SWIM protocol).
Чтобы задать приоритет в наборе реплик:
Нажмите Edit (Изменить) рядом с необходимым набором реплик.
Выполните прокрутку в окне Edit replica set (Изменить набор реплик), чтобы увидеть весь список серверов.
Перенесите реплики на необходимые места в списке приоритета и нажмите Save (Сохранить):

To enable eventual failover:
Нажмите Failover (Восстановление после отказа):
In the Failover control box, select the Eventual mode:

Важно
The stateful failover mode with Tarantool Stateboard is not recommended
for use on large clusters in production. If you have a high load production
cluster, use the stateful failover with etcd instead.
Leader appointments are polled from the external state provider.
Decisions are made by one of the instances with the failover-coordinator
role enabled. There are two options of external state provider:
- Tarantool Stateboard - you need to run instance of stateboard with command
tarantool stateboard.init.lua. - etcd v2 - you need to run and configure etcd cluster. Note that only etcd v2
API is supported, so you can still use etcd v3 with
ETCD_ENABLE_V2=true.
To enable stateful failover:
Run stateboard or etcd
Нажмите Failover (Восстановление после отказа):
In the Failover control box, select the Stateful mode:
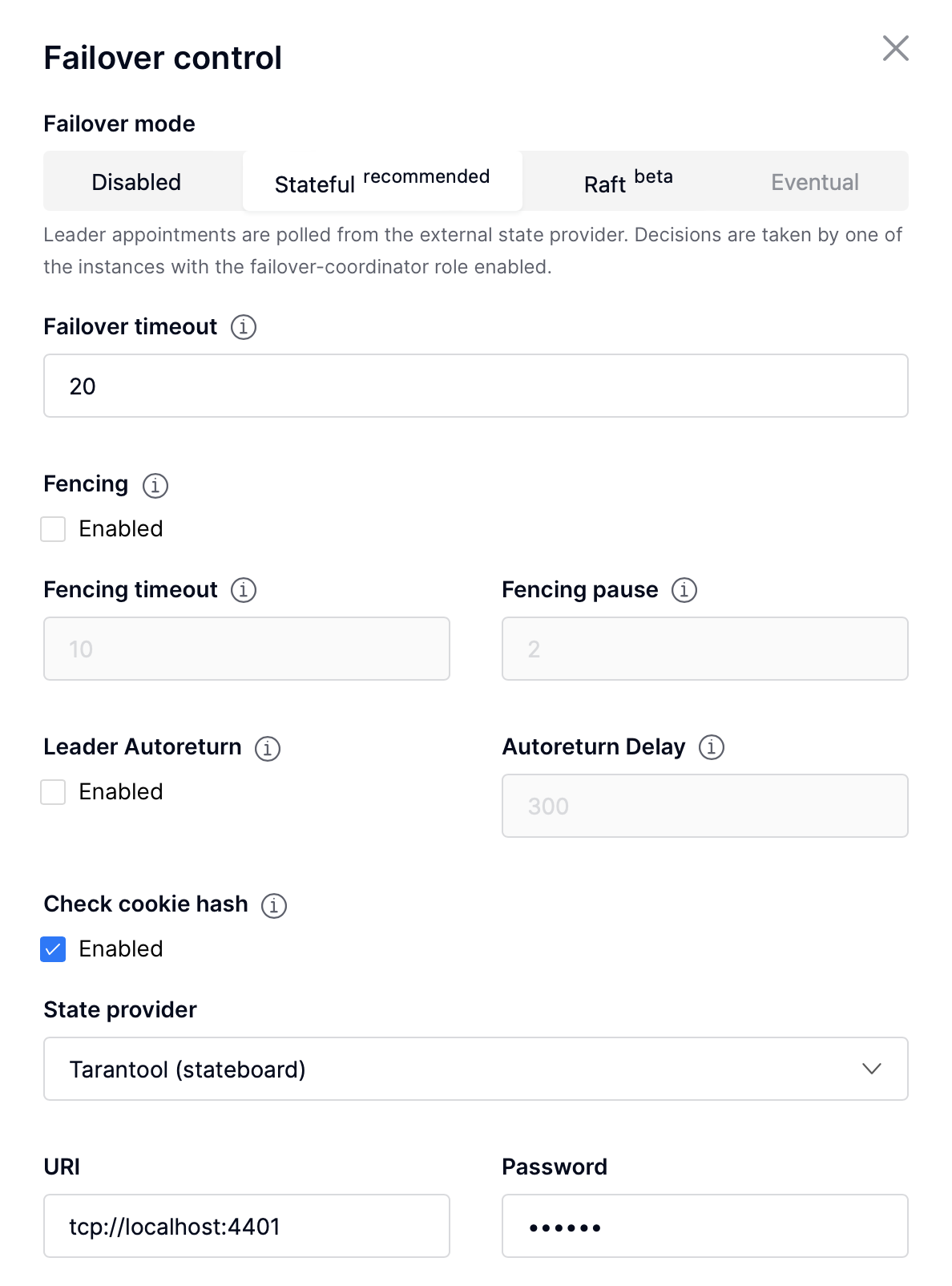
Check the necessary parameters.
In this mode, you can choose the leader with the Promote a leader button in the WebUI (or a GraphQL request).

You can also check state provider status in failover settings tab (it only works after stateful failover was enabled):

Важно
Raft failover in Cartridge is in beta. Don’t use it in production.
The replicaset leader is chosen by built-in Raft, then the other replicasets get information about leader change from membership. Raft parameters can be configured by environment variables.
To enable the Raft failover:
Make sure that your Tarantool version is higher than 2.10.0
Нажмите Failover (Восстановление после отказа):
In the Failover control box, select the Raft mode:
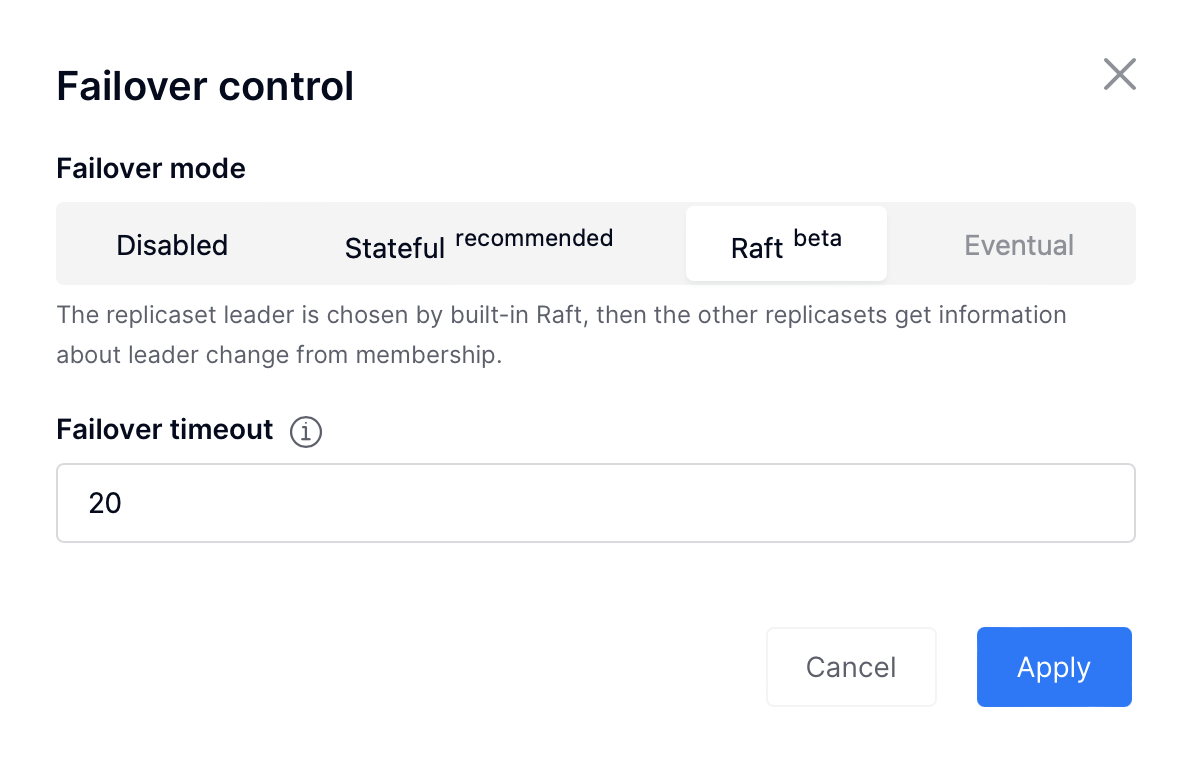
Check the necessary parameters.
In this mode, you can choose the leader with the Promote a leader button in the WebUI (or a
GraphQL request or manual call box.ctl.promote).
To change failover priority list:
Нажмите кнопку Edit (Изменить) рядом с необходимым набором реплик:

Выполните прокрутку в окне Edit replica set (Изменить набор реплик), чтобы увидеть весь список серверов. Мастером будет верхний сервер.

Перенесите необходимый сервер наверх и нажмите Save (Сохранить).
In case of eventual failover, the new master will automatically enter the read/write mode, while the ex-master will become read-only. This works for any roles.
На вкладке Users (Пользователи) можно включать и отключать аутентификацию, а также добавлять, удалять, изменять и просматривать пользователей, у которых есть доступ к веб-интерфейсу.

Обратите внимание, что вкладка Users (Пользователи) доступна только в том случае, если в веб-интерфейсе реализована авторизация.
Кроме того, некоторые функции (например, удаление пользователей) можно отключить в конфигурации кластера, что регулируется при помощи параметра auth_backend_name, который передается в cartridge.cfg().
В Tarantool встроен механизм асинхронной репликации. Как следствие, записи распределяются между репликами с задержкой, поэтому могут возникнуть конфликты.
Для предотвращения конфликтов используется специальный триггер space.before_replace. Он выполняется каждый раз перед внесением изменений в таблицу, для которой он был настроен. Функция триггера реализована на языке программирования Lua. Эта функция принимает в качестве аргументов исходные значения изменяемого кортежа и новые значения. Функция возвращает значение, которое используется для изменения результата операции: это будет новое значение измененного кортежа.
Для операций вставки старое значение отсутствует, поэтому в качестве первого аргумента передается нулевое значение nil.
Для операций удаления отсутствует новое значение, поэтому нулевое значение nil передается в качестве второго аргумента. Функция триггера также может возвращать нулевое значение nil, превращая эту операцию в удаление.
В примере ниже показано, как использовать триггер space.before_replace, чтобы предотвратить конфликты репликации. Предположим, у нас есть таблица box.space.test, которая изменяется в нескольких репликах одновременно. В этой таблице мы храним одно поле полезной нагрузки. Чтобы обеспечить согласованность, мы также сохраняем время последнего изменения в каждом кортеже этой таблицы и устанавливаем триггер space.before_replace, который отдает предпочтение новым кортежам. Ниже приведен код на Lua:
fiber = require('fiber')
-- определите функцию, которая будет изменять функцию test_replace(tuple)
-- добавьте временную метку к каждому кортежу в спейсе
tuple = box.tuple.new(tuple):update{{'!', 2, fiber.time()}}
box.space.test:replace(tuple)
end
box.cfg{ } -- восстановите из локальной директории
-- задайте триггер, чтобы избежать конфликтов
box.space.test:before_replace(function(old, new)
if old ~= nil and new ~= nil and new[2] < old[2] then
return old -- игнорируйте запрос
end
-- иначе примените как есть
end)
box.cfg{ replication = {...} } -- подпишитесь
В данном разделе описываются параметры, которые можно отслеживать в административной консоли.
Each Tarantool node (router/storage) provides an administrative console
(Command Line Interface) for debugging, monitoring, and troubleshooting. The
console acts as a Lua interpreter and displays the result in the human-readable
YAML format.
To connect to a Tarantool instance via the console, you can choose one of the commands:
Using the
ttCLI utility:$ tt connect <instance_hostname>:<port>
If you have cartridge-cli installed:
$ cartridge connect <instance_hostname>:<port>
If you ran Cartridge locally:
$ cartridge enter <node_name>
Old-fashioned way with
tarantoolctl:$ tarantoolctl connect <instance_hostname>:<port>
где <имя_хоста_экземпляра>:<порт> – это URI данного экземпляра.
Для получения информации об узлах хранения данных используйте vshard.storage.info().
tarantool> vshard.storage.info()
---
- replicasets:
<replicaset_2>:
uuid: <replicaset_2>
master:
uri: storage:storage@127.0.0.1:3303
<replicaset_1>:
uuid: <replicaset_1>
master:
uri: storage:storage@127.0.0.1:3301
bucket: <!-- статус сегментов
receiving: 0 <!-- сегменты в состоянии RECEIVING
active: 2 <!-- сегменты в состоянии ACTIVE
garbage: 0 <!-- сегменты в состоянии GARBAGE (запланированы к удалению)
total: 2 <!-- общее количество сегментов
sending: 0 <!-- сегменты в состоянии SENDING
status: 1 <!-- статус набора реплик
replication:
status: disconnected <!-- статус репликации
idle: <idle>
alerts:
- ['MASTER_IS_UNREACHABLE', 'Master is unreachable: disconnected']
| Код | Уровень критичности | Описание |
| 0 | Зеленый | Набор реплик работает в обычном режиме. |
| 1 | Желтый | Есть некоторые проблемы, но они не влияют на эффективность набора реплик (их стоит отметить, но они не требуют немедленного вмешательства). |
| 2 | Оранжевый | Набор реплик не восстановился после сбоя. |
| 3 | Красный | Набор реплик отключен. |
MISSING_MASTER— В конфигурации набора реплик отсутствует мастер-узел.Уровень критичности: Оранжевый.
Состояние кластера: Ухудшение работы запросов на изменение данных к набору реплик.
Решение: Задайте мастер-узел для набора реплик, используя API.
UNREACHABLE_MASTER— Отсутствует соединение между мастером и репликой.Уровень критичности:
- Если значение бездействия не превышает порог T1 (1 с) — Желтый,
- Если значение бездействия не превышает порог T2 (5 с) — Оранжевый,
- Если значение бездействия не превышает порог T3 (10 с) — Красный.
Состояние кластера: При запросах на чтение из реплики данные могут быть устаревшими по сравнению с данными на мастере.
Решение: Повторно подключитесь к мастеру: устраните проблемы с сетью, сбросьте текущий мастер, переключитесь на другой мастер.
LOW_REDUNDANCY— У мастера есть доступ только к одной реплике.Уровень критичности: Желтый.
Состояние кластера: Коэффициент избыточности хранения данных равен 2. Он ниже минимального рекомендуемого значения для использования в производстве.
Решение: Проверить конфигурацию кластера:
- Если в конфигурации указан только один мастер и одна реплика, рекомендуется добавить хотя бы еще одну реплику, чтобы коэффициент избыточности достиг 3.
- Если в конфигурации указаны три или более реплик, проверьте статусы реплик и сетевое соединение между репликами.
INVALID_REBALANCING— Нарушен инвариант балансировки. Во время миграции узел хранилища может либо отправлять сегменты, либо получать их. Поэтому не должно быть так, чтобы набор реплик отправлял сегменты в один набор реплик и одновременно получал сегменты из другого набора реплик.Уровень критичности: Желтый.
Состояние кластера: Балансировка приостановлена.
Решение: Есть две возможные причины нарушения инварианта:
- Отказ балансировщика.
- Статус сегмента был изменен вручную.
В любом случае обратитесь в техническую поддержку Tarantool.
HIGH_REPLICATION_LAG— Отставание реплики превышает порог T1 (1 с).Уровень критичности:
- Если отставание не превышает порог T1 (1 с) — Желтый;
- Если отставание превышает порог T2 (5 с) — Оранжевый.
Состояние кластера: При запросах только на чтение из реплики данные могут быть устаревшими по сравнению с данными на мастере.
Решение: Проверьте статус репликации на реплике. Более подробные инструкции приведены в руководстве по разрешению проблем по.
OUT_OF_SYNC— Нарушилась синхронизация. Отставание превышает порог T3 (10 с).Уровень критичности: Красный.
Состояние кластера: При запросах только на чтение из реплики данные могут быть устаревшими по сравнению с данными на мастере.
Решение: Проверьте статус репликации на реплике. Более подробные инструкции приведены в руководстве по разрешению проблем по.
UNREACHABLE_REPLICA— Одна или несколько реплик недоступны.Уровень критичности: Желтый.
Состояние кластера: Коэффициент избыточности хранения данных для данного набора реплик меньше заданного значения. Если реплика стоит следующей в очереди на балансировку (в соответствии с настройками веса), запросы перенаправляются в реплику, которая все еще находится в очереди.
Решение: Проверьте сообщение об ошибке и выясните, какая реплика недоступна. Если реплика отключена, включите ее. Если это не поможет, проверьте состояние сети.
UNREACHABLE_REPLICASET— Все реплики, кроме текущей, недоступны. Уровень критичности: Красный.Состояние кластера: Реплика хранит устаревшие данные.
Решение: Проверьте, включены ли другие реплики. Если все реплики включены, проверьте наличие сетевых проблем на мастере. Если реплики отключены, сначала проверьте их: возможно, мастер работает правильно.
Для получения информации о роутерах используйте vshard.router.info().
tarantool> vshard.router.info()
---
- replicasets:
<replica set UUID>:
master:
status: <available / unreachable / missing>
uri: <!-- URI мастера
uuid: <!-- UUID экземпляра
replica:
status: <available / unreachable / missing>
uri: <!-- URI реплики, используемой для slave-запросов
uuid: <!-- UUID экземпляра
uuid: <!-- UUID набора реплик
<replica set UUID>: ...
...
status: <!-- статус роутера
bucket:
known: <!-- количество сегментов с известным назначением
unknown: <!-- количество других сегментов
alerts: [<alert code>, <alert description>], ...
| Код | Уровень критичности | Описание |
| 0 | Зеленый | Роутер работает в обычном режиме. |
| 1 | Желтый | Некоторые реплики недоступны, что влияет на скорость выполнения запросов на чтение. |
| 2 | Оранжевый | Работа запросов на изменение данных ухудшена. |
| 3 | Красный | Работа запросов на чтение данных ухудшена. |
Примечание
В зависимости от характера проблемы используйте либо UUID реплики, либо UUID набора реплик.
MISSING_MASTER— В конфигурации одного или нескольких наборов реплик не указан мастер.Уровень критичности: Оранжевый.
Состояние кластера: Частичное ухудшение работы запросов на изменение данных.
Решение: Укажите мастера в конфигурации.
UNREACHABLE_MASTER— Роутер потерял соединение с мастером одного или нескольких наборов реплик.Уровень критичности: Оранжевый.
Состояние кластера: Частичное ухудшение работы запросов на изменение данных.
Решение: Восстановите соединение с мастером. Сначала проверьте, включен ли мастер. Если он включен, проверьте состояние сети.
SUBOPTIMAL_REPLICA— Есть реплика для запросов только для чтения, но эта реплика не оптимальна относительно сконфигурированных весов. Это значит, что оптимальная реплика недоступна.Уровень критичности: Желтый.
Состояние кластера: Запросы только на чтение направляются на резервную реплику.
Решение: Проверьте статус оптимальной реплики и ее сетевого подключения.
UNREACHABLE_REPLICASET— Набор реплик недоступен как для запросов только на чтение, так и для запросов на изменение данных.Уровень критичности: Красный.
Состояние кластера: Частичное ухудшение работы запросов на изменение данных и на чтение данных.
Решение: В наборе реплик недоступны мастер и реплика. Проверьте сообщение об ошибке, чтобы найти этот набор реплик. Исправьте ошибку, как описано в решении ошибки UNREACHABLE_REPLICA.
Cartridge displays cluster and instances issues in WebUI:

Replication
- critical: «Replication from … to … isn’t running» –
when
box.info.replication.upstream == nil; - critical: «Replication from … to … state «stopped»/»orphan»/etc. (…)»;
- warning: «Replication from … to …: high lag» –
when
upstream.lag > box.cfg.replication_sync_lag; - warning: «Replication from … to …: long idle» –
when
upstream.idle > 2 * box.cfg.replication_timeout;

Cartridge can propose you to fix some of replication issues by restarting replication:

- critical: «Replication from … to … isn’t running» –
when
Failover:
- warning: «Can’t obtain failover coordinator (…)»;
- warning: «There is no active failover coordinator»;
- warning: «Failover is stuck on …: Error fetching appointments (…)»;
- warning: «Failover is stuck on …: Failover fiber is dead» – this is likely a bug;
Switchover:
- warning: «Consistency on … isn’t reached yet»;
Clock:
- warning: «Clock difference between … and … exceed threshold» –
limits.clock_delta_threshold_warning;
- warning: «Clock difference between … and … exceed threshold» –
Memory:
- critical: «Running out of memory on …» – when all 3 metrics
items_used_ratio,arena_used_ratio,quota_used_ratiofrombox.slab.info()exceedlimits.fragmentation_threshold_critical; - warning: «Memory is highly fragmented on …» - when
items_used_ratio > limits.fragmentation_threshold_warningand botharena_used_ratio,quota_used_ratioexceed critical limit;
- critical: «Running out of memory on …» – when all 3 metrics
Configuration:
- warning: «Configuration checksum mismatch on …»;
- warning: «Configuration is prepared and locked on …»;
- warning: «Advertise URI (…) differs from clusterwide config (…)»;
- warning: «Configuring roles is stuck on … and hangs for … so far»;

Cartridge can propose you to fix some of configuration issues by force applying configuration:

Vshard:
- various vshard alerts (see vshard docs for details);
- warning: warning: «Group «…» wasn’t bootstrapped: …»;
- warning: Vshard storages in replicaset %s marked as «all writable».
Alien members:
- warning: «Instance … with alien uuid is in the membership» – when two separate clusters share the same cluster cookie;

Expelled instances:
- warning: «Replicaset … has expelled instance … in box.space._cluster» - when instance was expelled from replicaset, but still remains in box.space._cluster;
Deprecated space format:
- warning: «Instance … has spaces with deprecated format: space1, …»
Raft issues:
- warning: «Raft leader idle is 10.000 on … . Is raft leader alive and connection is healthy?»
Unhealthy replicasets:
- critical: «All instances are unhealthy in replicaset».

The issue is produced when all instances in the replicaset are unhealthy and not disabled. You can disable both to get rid of the issue.

Custom issues (defined by user):
- Custom roles can announce more issues with their own level, topic
and message. See
custom-role.get_issues.
- Custom roles can announce more issues with their own level, topic
and message. See
Disable instances suggestion:
When some instances are unhealthy, Cartridge can suggest you to disable them:

Since Tarantool Enterprise supporting compression, Cartridge can check if you have spaces where you can use compression. To enable it, click on button «Suggestions». Note that the operation can affect cluster perfomance, so choose the time to use it wisely.

You will see the warning about cluster perfomance and then click «Continue».

You will see information about fields that can be compressed.

You can check some general instance info in WebUI. To see it, click on «Server details button».

And then choose one of the tabs to see various parameters:

Cartridge provides a way to control VShard rebalancer via WebUI and GraphQL API. You can operate rebalancer mode and change rebalancer settings on each replicaset or instance. It can be useful to stop rebalancer or choose rebalancer instance manually.
To change rebalancer mode, click on «Rebalancer mode» button next to «Failover» button and choose desired mode:
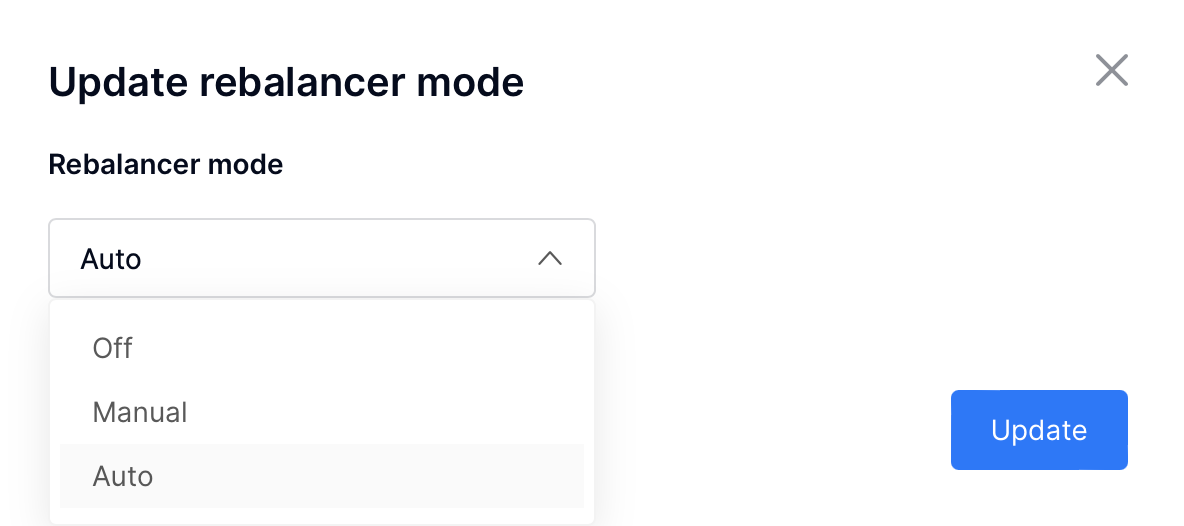
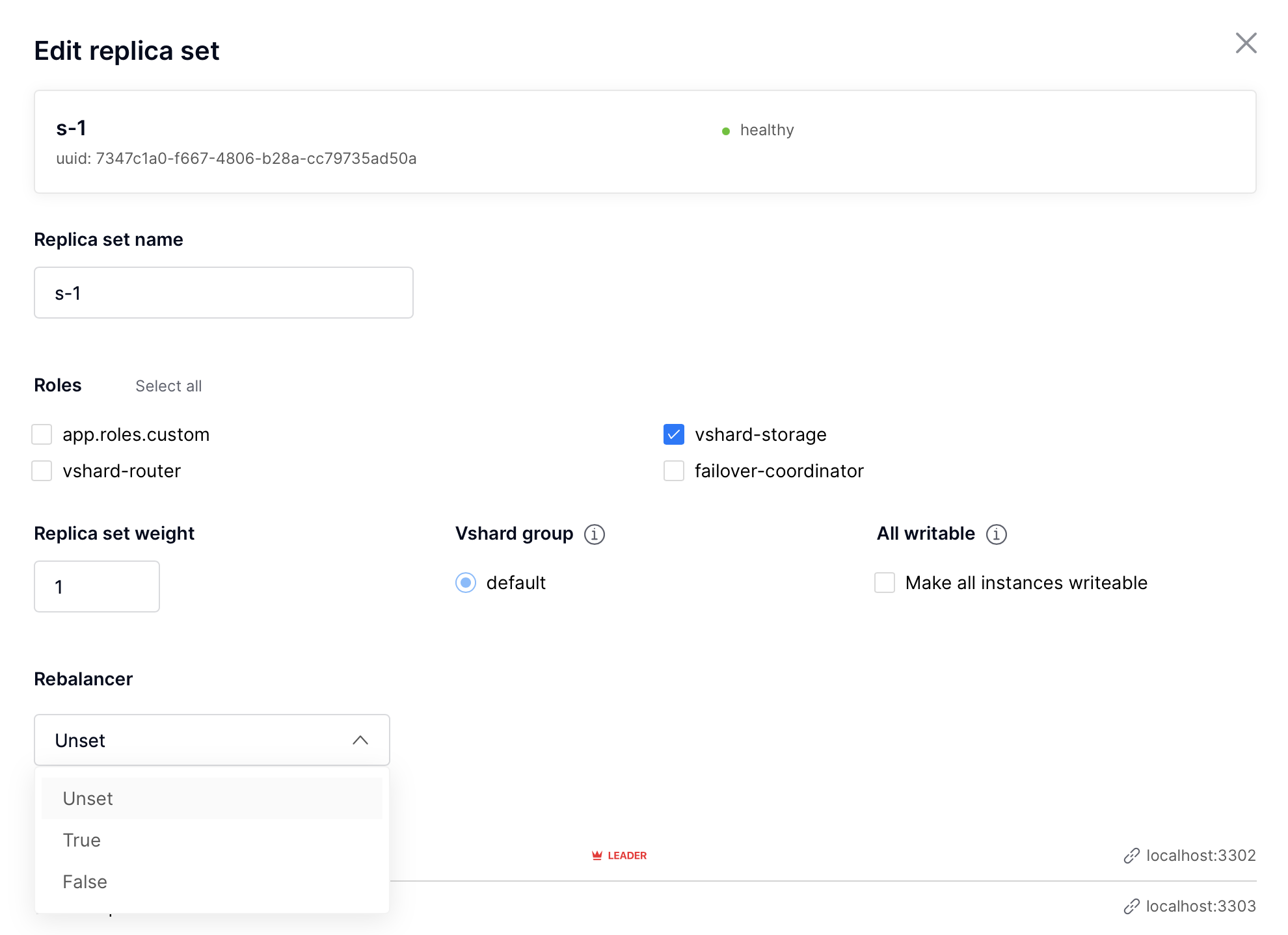
To change rebalancer settings on replicaset, click on «Edit replicaset» button and then choose desired rebalancer state («unset» means abcence of the value):
To change rebalancer settings on instance, click on «…» button next to it:

And then choose desired rebalancer state («unset» means abcence of the value):

You can see current settings and actual rebalancer state in WebUI. Black R means
that rebalancer is true on this instance/replicaset, grey R means that rebalancer
is false on this instance/replicaset, and green R means that rebalancer
is running on this instance:

See VShard documentation to get more information about rebalancer usage.
Since Cartridge 2.10.0 when using migrations 1.0.0 or higher, you can use
WebUI to monitor and control you migrations.
At first, open migrations tab in the left menu. From here, you can see all migrations status and can start migrations.

After clicking on «Migration Up» button, you will see the result:

In some cases it could be useful to change cluster-cookie (e.g. when you need to fix a broken cluster). To do it, perform next actions:
(Optional) If you use stateful failover:
-- remember old cookie hash local cluster_cookie = require('cartridge.cluster-cookie') local old_hash = cluster_cookie.get_cookie_hash()
Change cluster-cookie on each instance:
local cluster_cookie = require('cartridge.cluster-cookie') cluster_cookie.set_cookie(new_cookie) require('membership').set_encryption_key(cluster_cookie.cookie()) if require('cartridge.failover').is_leader() then box.schema.user.passwd(new_cookie) end
(Optional) If you use stateful failover:
-- update cookie hash in a state provider require('cartridge.vars').new('cartridge.failover').client:set_identification_string( cluster_cookie.get_cookie_hash(), old_hash)
Call
apply_configin cluster to reapply changes to each instance:local confapplier = require('cartridge.confapplier') local clusterwide_config = confapplier.get_active_config() return confapplier.apply_config(clusterwide_config)
It’s possible that some instances have a broken configuration. To do it, perform next actions:
Try to reapply configuration forcefully:
cartridge.config_force_reapply(instaces_uuids) -- pass here uuids of broken instances
If it didn’t work, you could try to copy a config from healthy instance:
- Stop broken instance and remove it’s
configdirectory. Don’t touch any other files in working directory. - Copy
configdirectory from a healthy instance to broken one’s directory. - Start broken instance and check if it’s working.
- If nothing had worked, try to carefully remove a broken instance from cluster and setup a new one.
- Stop broken instance and remove it’s
Во время перехода на более новую версию Tarantool, пожалуйста, не забудьте:
- Остановить кластер
- Убедиться, что включена опция
upgrade_schema - Затем снова запустить кластер
Это автоматически запустит box.schema.upgrade() на лидере в соответствии с приоритетом (failover priority) в настройках набора реплик.
См. раздел Аварийное восстановление в руководстве по Tarantool.
См. раздел Резервное копирование в руководстве по Tarantool.